



We are witnessing a thrilling period marked by AI progress reshaping professional fields.
Since its debut, GPT-3 has supported professionals in search engine marketing (SEM) by aiding them in their content-related duties.
The introduction of ChatGPT in late 2022 catalyzed a trend towards developing AI assistants.
By the conclusion of 2023, OpenAI had rolled out GPT models that integrate instructions, supplementary information, and task execution capabilities.
The Promise Of GPTs
GPTs have opened the door to achieving the long-envisioned dream of a personal assistant. Conversational LLMs embody an optimal human-machine interface.
Creating robust AI assistants requires solving numerous challenges: simulating reasoning, preventing hallucinations, and improving the ability to leverage external tools.
Our Journey To Developing An SEO Assistant
Over the past few months, my longstanding collaborators Guillaume and Thomas, along with myself, have been dedicated to researching this topic.
Here, I will outline the development process of our initial prototype for an SEO assistant.
An SEO Assistant, Why?
Our objective is to develop an assistant capable of:
- Generating content based on provided briefs.
- Providing comprehensive SEO industry insights. It should offer nuanced responses to queries like “Should there be multiple H1 tags per page?” or “Is TTFB a ranking factor?”
- Interacting with SaaS tools. Many of these tools have varying degrees of complexity in their graphical user interfaces. Enabling interaction through dialogue simplifies their usage.
- Planning tasks such as managing a complete editorial calendar and performing regular reporting tasks like creating dashboards.
Regarding the first task, LLMs are already quite proficient as long as they are constrained to use accurate information.
The aspect of planning tasks remains largely speculative at this stage.
Therefore, our efforts are concentrated on integrating data into the assistant using RAG and GraphRAG approaches, as well as leveraging external APIs.
The RAG Approach
Initially, our focus will be on developing an assistant using the retrieval-augmented generation (RAG) approach.
RAG mitigates model hallucinations by supplementing internal training data with information from external sources. Conceptually, it resembles interacting with a knowledgeable individual who has access to a search engine.

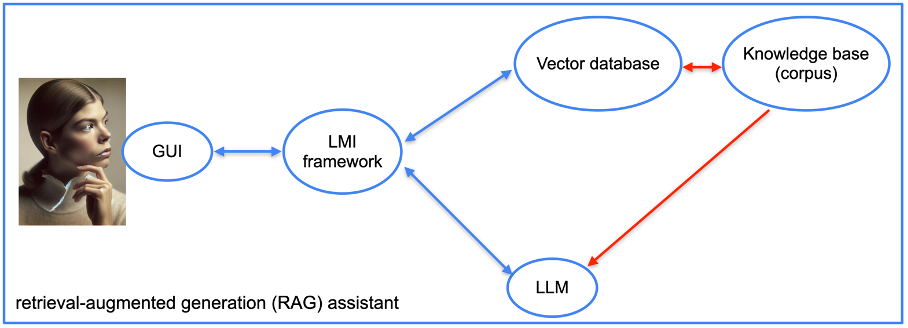
For our assistant’s foundation, we have opted to utilize a vector database. Numerous options exist, including Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS, among others. Our prototype will utilize the vector database provided by LlamaIndex.
Additionally, integrating a language model integration (LMI) framework is crucial. This framework facilitates connecting the language model (LLM) with databases and documents. Various frameworks are available for this purpose, such as LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin, and others. For our project, we have selected LangChain and LlamaIndex.
Once the software stack is chosen, implementation proceeds straightforwardly. The framework transforms provided documents into vectors that encode their content.
Numerous technical parameters can enhance results, with specialized search frameworks like LlamaIndex demonstrating robust native performance.
For our proof-of-concept, we provided several SEO books in French and selected webpages from well-known SEO websites.
Implementing RAG helps reduce hallucinations and provides more comprehensive responses. The next image showcases an example where we compare an answer from a standard LLM and the same LLM enhanced with our RAG approach.


In this instance, the RAG-enhanced response includes slightly more detailed information compared to the response from the LLM alone.
The GraphRAG Approach
RAG models enhance LLMs by incorporating external documents, yet they encounter challenges in effectively integrating these sources and extracting the most pertinent information from a vast corpus.
When an answer necessitates amalgamating information from multiple documents, the RAG approach may falter. To address this issue, we preprocess textual data to extract its underlying semantic structure.
This involves constructing a knowledge graph, a data structure that depicts relationships between entities in the form of subject-relation-object triples.
Below is an illustration demonstrating several entities and their interrelationships.

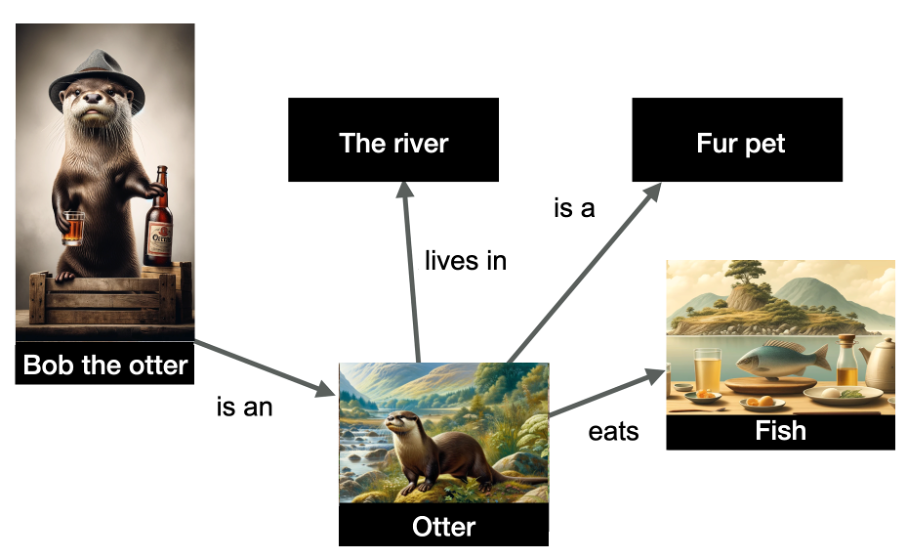
The graph represents entities such as “Bob the otter” (a named entity), as well as “the river,” “otter,” “fur pet,” and “fish,” with relationships depicted on the edges.
This structured data reveals that Bob the otter is classified as an otter, otters inhabit rivers, consume fish, and are kept as pets for their fur. Knowledge graphs are invaluable for inference: based on this graph, I can deduce that Bob the otter is indeed a fur pet!
Creating knowledge graphs has long been a task handled by NLP techniques. However, LLMs streamline this process due to their text processing capabilities. Thus, we enlist an LLM to construct the knowledge graph.

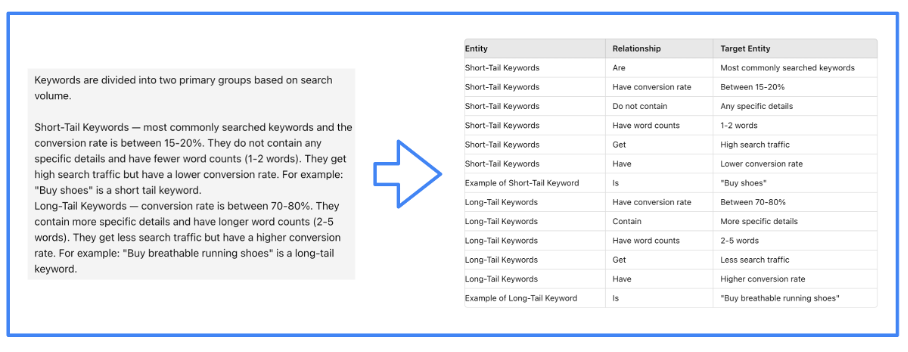
The efficiency with which the LLM undertakes this task is guided by the LMI framework. In our project, we utilize LlamaIndex for this purpose.
Moreover, the complexity of our assistant’s structure increases notably when employing the graphRAG approach (refer to the subsequent image).

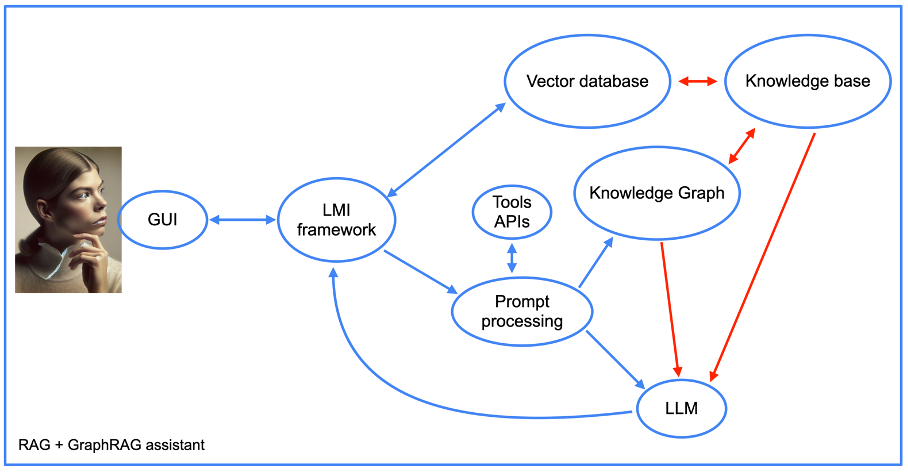
We will revisit the integration of tool APIs later. For now, we observe the components of the RAG approach alongside the incorporation of a knowledge graph. Notably, there is a crucial “prompt processing” element.
This segment of the assistant’s code initially translates prompts into database queries. Subsequently, it reverses this process by generating a coherent, human-readable response based on outputs from the knowledge graph.
The following image displays the actual code used for prompt processing. As depicted, we employed NebulaGraph, one of the pioneering projects to implement the GraphRAG approach.

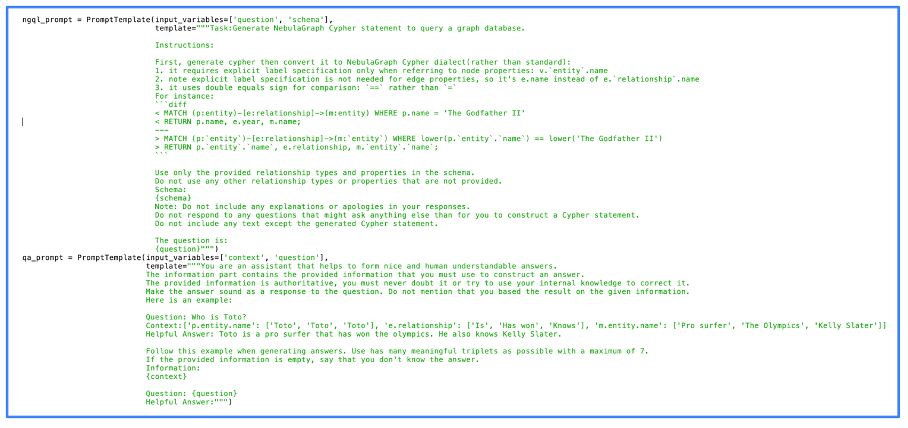
The prompts themselves appear straightforward, with much of the computational heavy lifting handled directly by the LLM. The efficacy of the results hinges largely on the quality of the LLM, even when employing open-source models.
We populated the knowledge graph with the same information utilized for the RAG. Does this yield better quality answers? Let’s examine the same example.


I leave it to the reader to judge whether the information presented here surpasses previous approaches, but I find it to be more organized and comprehensive. However, one drawback of GraphRAG is the latency in delivering responses, which I will address further in discussing user experience issues.
Integrating SEO Tools Data
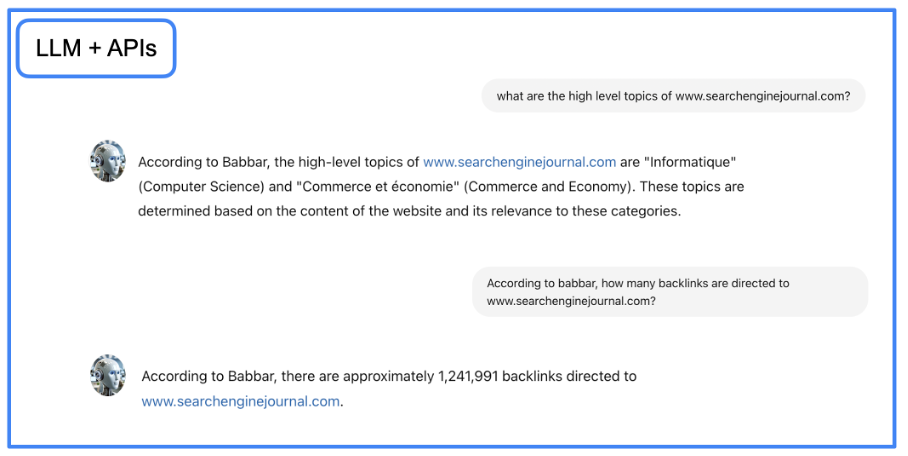
Currently, we have an assistant capable of accurately generating and delivering knowledge. However, our objective now is to enhance the assistant’s capability to retrieve data from SEO tools. To achieve this, we will leverage LangChain for interacting with APIs through natural language.
This involves defining functions that instruct the language model (LLM) on how to utilize specific APIs. In our project, we utilized the API provided by babbar.tech (Full disclosure: I am the CEO of the company developing this tool).

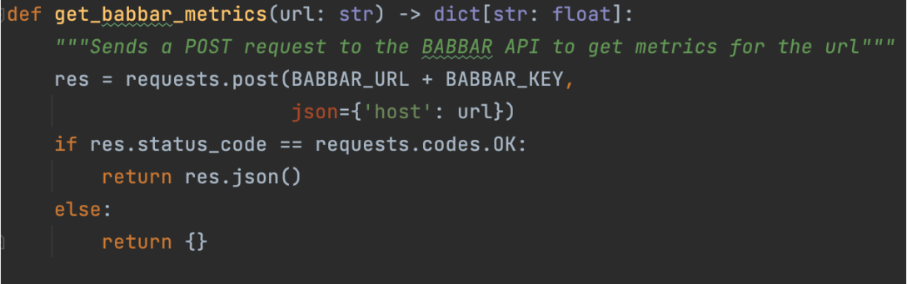
The diagram illustrates how the assistant can collect information such as linking metrics for a given URL. Subsequently, we specify at the framework level (specifically using LangChain here) that this function is accessible.
The following three lines instantiate a LangChain instance based on the aforementioned function and initialize a chat session for formulating responses related to the gathered data. Notably, a temperature setting of zero is applied, ensuring the output from GPT-4 remains factual and devoid of creativity, which is ideal for extracting data from tools.
Again, the LLM handles most of the process: translating the natural language query into an API request and then converting the API’s output back into natural language.

For detailed instructions and steps, you can download the Jupyter Notebook file, which guides you through setting up the GraphRAG conversational agent in your local environment.
Once you’ve implemented the provided code, you can interact with the newly created agent using the Python code snippet below in your Jupyter notebook. Simply set your prompt within the code and execute it.
It’s (Almost) A Wrap
We’ve developed a proof-of-concept utilizing an LLM (such as GPT-4) integrated with RAG and GraphRAG methodologies, enhanced by access to external APIs. This showcases a potential future for SEO automation.
This approach grants us seamless access to comprehensive domain knowledge and simplifies interaction with even the most sophisticated tools (we’ve all grappled with cumbersome GUIs in top-tier SEO tools).
However, two challenges persist: latency in responses and the perception of conversing with a bot.
The first challenge stems from the processing time required to traverse between the LLM and graph or vector databases. Our current project necessitates up to 10 seconds to provide answers to highly intricate queries.
Addressing this requires exploring limited options: scaling hardware resources or anticipating enhancements from the software components we utilize.
The second challenge is more complex. Despite LLMs mimicking human tone and writing, their proprietary interface remains a barrier.
Both issues can be ingeniously resolved by employing a familiar text interface widely used by humans, where latency is typical due to asynchronous communication.
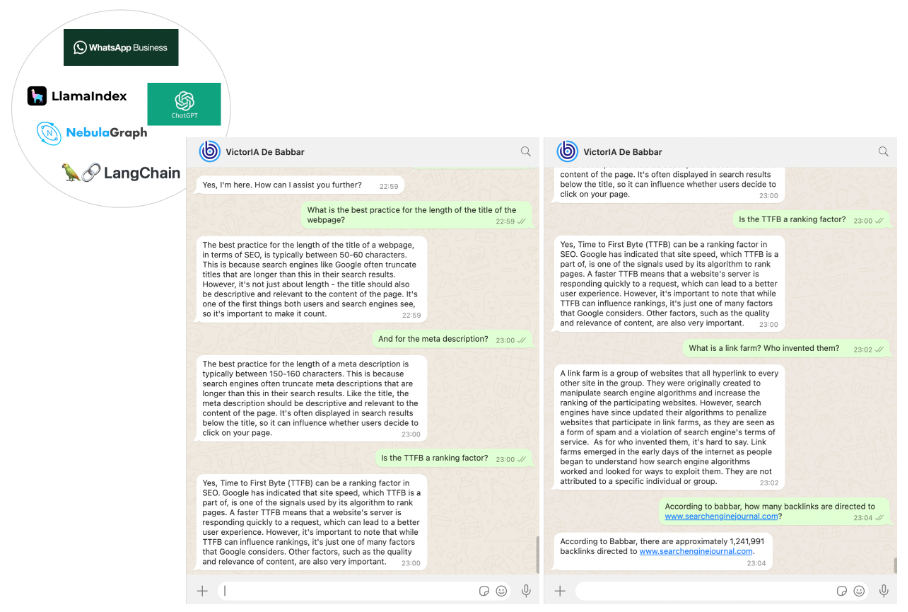
We opted for WhatsApp as our SEO assistant’s communication channel. Implementing this was straightforward using the WhatsApp Business platform integrated with Twilio’s Messaging APIs.
Ultimately, we created an SEO assistant named VictorIA, blending “Victor” (after Victor Hugo, the renowned French writer) with “IA” (the French acronym for Artificial Intelligence), as depicted in the accompanying image.

Conclusion
Our project marks just the initial stride in an exhilarating journey. Assistants have the potential to redefine our industry. By leveraging GraphRAG alongside APIs, we’ve empowered LLMs, enabling organizations to establish their own solutions.
These assistants can streamline the onboarding process for new junior team members (reducing their reliance on senior staff for basic inquiries) and serve as a knowledge repository for customer support teams.
We’ve made the source code available for those capable of implementing it directly. Most sections of the code are straightforward, though the Babbar tool-related part can be skipped or substituted with APIs from alternative tools.
It’s crucial to understand how to configure a Nebula graph store instance, ideally on-premises, as Docker deployment of Nebula may lead to suboptimal performance. While the setup process is documented, it may initially appear complex.
To assist beginners, we’re considering creating a tutorial soon to facilitate a smooth start.
Original news from SearchEngineJournal